User Data in Refiner
At Refiner, we distinguish between two types of data stored in your Refiner environment. First, there is configuration data such as surveys, dashboards, segments, alerts, etc.
Secondly, there is user data which consists of user profiles, survey responses, user traits and tracked events.
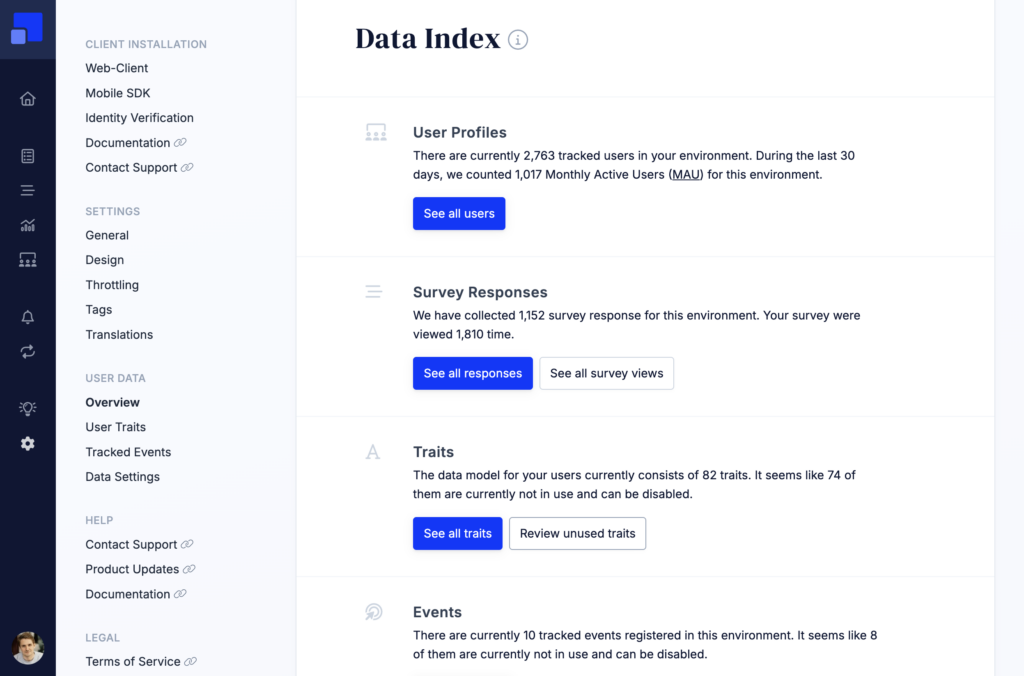
In the settings of your environment, you’ll find a Data Index that gives you a quick overview and access to all user data store in your Refiner account. Y
Please note: Keeping your user data safe and available is our highest priority. You have full control over which user data is stored in your Refiner account and how long we should keep it for your. Your user data belongs to you and we’ll never sell or use it in any way. You can read more about data security and compliance at Refiner here.