User Traits
Introduction
You can think of Traits as a high level description of all the user data that is stored in your Refiner environment. If you think about your user data as a giant spreadsheet, a Trait would represent one column in your spreadsheet.
Traits are created automatically whenever we receive user data for your Refiner environment:
- When you identify a user, a trait is created for each data attribute that you include in the identifyUser call.
- When we receive a new survey response, a trait is created for each survey question based on the question identifier
- Computed traits are automatically generated when new user data is available, for example “User first seen”, “Last survey submission”, “Total survey submissions”, etc. (see below).
You can find all trait data we have on record for a given user in the User Details Panel.
Trait types
Refiner distinguished between the following four types of traits.
Survey response data
Survey response data represents all information that we collected for a user when they replied to one of your surveys. Trait names are created automatically based on the Question Identifier you chose for your survey questions.
As the name suggests, survey response data is linked to survey responses. When a user responds multiple times to a survey – generating multiple survey responses – you’ll see one data value for each response.
Metadata
Metadata is generated and updated automatically for each user, whenever an important event happens for their user profile. The information includes things like the time we first saw a user, how many surveys they saw, etc.
Contact data
Contact data contains all information that was sent to us through the “identifyUser” method, for example when you identify a user with our JavaScript SDK, our Mobile SDK, a data integration or an API call.
Contact data always represents the latest set of data we received for a user. Whenever new data is received through an “identifyUser” method call, previously stored data is overwritten. Unlike survey response data, contact data is not tied to a specific timed event like a survey response.
Account data
Besides storing data for each individual user, Refiner also lets you store data on an “account” level. An account groups multiple users in one entity. You can think of accounts as “groups” or “companies”.
Account traits are only created when you explicitly provide an account object when identifying users with our JavaScript SDK, our Mobile SDK or through our API.
Account data behaves in the same way as Contact data and it always represents the latest set of data which we received from you.
Trait properties
Data type
Refiner supports the following data types:
- Strings – 10.000 characters max length
- Integer numbers – ranging from -2147483647 to 2147483647
- Dates – ISO date format or Linux timestamp
Strings and Integer numbers are detected automatically by our APIs.
To import dates to Refiner, your field identifier needs to follow a certain pattern. Our APIs detect dates if the field name ends with “_at” (e.g. created_at, upgraded_at, another_event_at, …) or “_date” (e.g. subscription_date, last_login_date, …). You can provide dates as ISO strings or Unix Timestamps.
Finite data
A trait can be labeled as a “Finite dataset”, which means that trait has a limited and well defined number of possible values. For example, a list all countries or the activation status of a user, are both finite datasets. The opposite of a finite dataset are continuous datasets, such as arbitrary strings (e.g. “first name”) or numbers (e.g. “login count”).
When a dataset is set to “Finite”, you’ll have access to different kind of filters when creating a data-driven segment.
Refiner tries to figure out automatically if a field holds a finite or continuous dataset, based on the name of the field (e.g. “country”, “role”, …). If Refiner didn’t get it right, you can change switch a data field from finite to continuous and vice versa anytime.
Reserved traits
Refiner has a couple of reserved field identifiers which you should be aware of.
If you use any of the following data field, Refiner will interpret the provided data in a certain way or ignore the provided data.
| id | A unique string identifier for the current user. This field is the mandatory if you don’t provide an email address. |
| country | If provided when identifying a user we use the value to overwrite the automatically detected country of the user. The provided value is also used for the country targeting feature of in-app surveys. The expected value is a two characters ISO 3166 country code. |
| current_screen | Reserved for tracking the current screen of a mobile app user (only if option activated). |
| current_url | Reserved for tracking the current URL of a web app user (only if option activated). |
| The email address of a the current user. This field is optional. If provided without a user Id, Refiner uses the email address as the user identifier. | |
| first_seen_at | The date and time when a user was first seen by any of our APIs. The date value is calculated automatically and can’t be overwritten. |
| form_submissions_count | The number of times a user responded to a survey. The date value is calculated automatically and can’t be overwritten. |
| form_views_count | The number of times a user saw a survey. The date value is calculated automatically and can’t be overwritten. |
| ip_address | Reserved for tracking the IP address of a user (only if option activated). |
| last_seen_at | The date and time when a user was last seen by any of our APIs. The date value is calculated automatically and can’t be overwritten. |
| last_form_view_at | The date and time a user saw a survey the last time. The date value is calculated automatically and can’t be overwritten. |
| last_form_submission_at | The date and time a user responded to a survey the last time. The date value is calculated automatically and can’t be overwritten. |
| locale | If provided when identifying a user with our JavaScript SDK, we use the locale value to overwrite the automatically detected language of a user. The provided value is then used for the language targeting option, as well as for the multi-language translation feature. The expected value is a two characters ISO 639-1 code. |
| locale_used | The actual language a survey was translated to when the user responded to it. |
| mobile_platform | Reserved for tracking the mobile platform (ios, android) of a mobile app user (only if option activated). |
| mobile_os_version | Reserved for tracking the OS version of a mobile app user (only if option activated). |
| mobile_sdk_version | Reserved for tracking the SDK version of a mobile app user (only if option activated). |
| web_browser | Reserved for tracking the web browser name of a web app user (only if option activated). |
| web_device_os | Reserved for tracking the OS name of a web app user (only if option activated). |
| web_device_type | Reserved for tracking the device type (desktop, tablet, mobile) of a web app user (only if option activated). |
| write_operation | Allows you to switch the write operation from “append” to “replace” when calling “identify-user” route of the REST API. |
Please note that many of the reserved trait names are metadata fields (e.g. country, current_url, locale, …) that can be collected automatically by enabling the metadata collection option.
Manage traits
The Traits Table is where you find a description of all traits that are stored in your Refiner environment for your users. The page lets you rename, disable and delete traits.
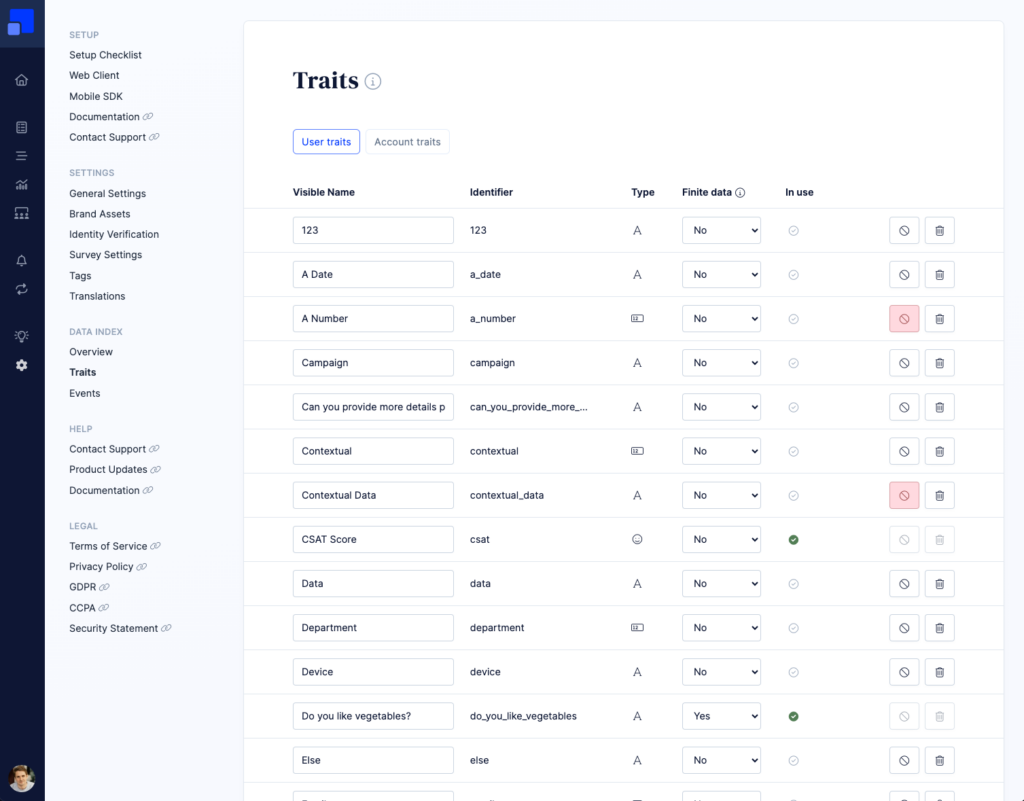
Rename traits
Trait names are created automatically based on the identifier used in your surveys or when calling our API. You can rename traits if you want to add more clarity to your Refiner account.

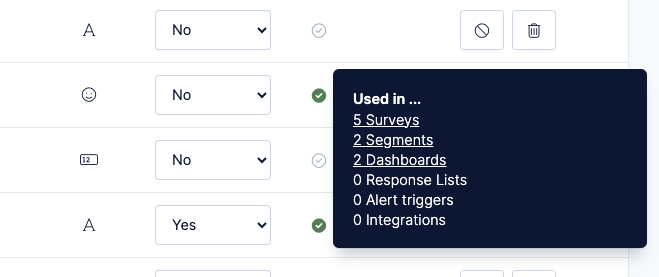
Get usage info
For each trait you’ll find check icon that indicates if a trait is currently used in your environment. Clicking on the icon will reveal detailed usage information.
Delete and disable traits
You can choose to delete a trait or disable it. When you delete a trait, it will be removed from your environment and all associated data with it. A deleted trait will reappear if we receive new data using the same identifier.
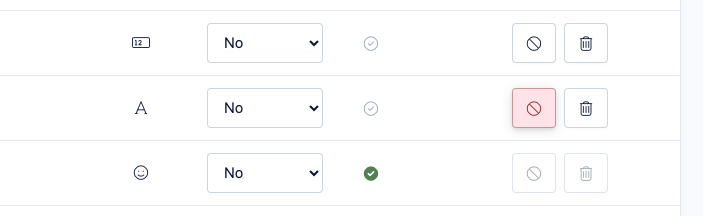
When you disable a trait, Refiner will ignore all incoming data for it and you won’t see the trait in other places in your dashboard.
You can also create traits manually if needed. For example if you want start building segments before connecting an actual data source to your environment.
Flag as finite data
You can flag a Trait as being a “Finite data” (see description above). When you flag a trait as such, you’ll see more adapted filter options when creating a data-driven segment.
Limitations
The number of traits is limited to 3.000 traits per environment. Once this number is reached, we won’t create new traits on data reception which might lead to data loss. If you think you’ll exceed 1.000 traits, please contact our support team.